GhostVoice AI

This is a project to make a desktop ghost (inspired by Destiny 2) which can speak in conversation with a user. Mine will probably go toward HW help and alike full of files that describe parts of classes I am currently studying in!
Supplies

This project requires:
- 3D printer and filament -- Files included below
- Paint to color the 3D print (I used white, orange, black spray paint -- Rust-Oleum brand has never failed me)
- Lots of wires (male to male, female to male, female to female)
- Neo pixel strip 30 or Adafruit TFT Gizmo
- USB microphone
- Micro USB (male) to USB (female) splitter
- SD card (32gb or bigger)
- Mouse and keyboard
- Bluetooth speaker or if high volume not needed audio jack female and hamburger speaker or equivalent
- Lots of patience (Linux permissioning on this + Adafruit neo pixel pin errors + ALSA handling forms a real bear of a problem, at least to me)
- Raspberry Pi Zero 2W
- Portable Charger (USB (male) to Micro USB (male))
Loading the RPOS Onto the Pi Zero 2W
First we need to load RPOS onto the chip
- Here is a great great guide that I would trust 1000x more than my type up (https://www.tomshardware.com/how-to/set-up-raspberry-pi)
- First we need download the OS onto out SD with from here
- We can then place it onto our SD card slot and the Raspberry Pi should boot -- all basic default settings will do for this project
- Now we need pip install all the packages we need, the list of packages we need include blinka, neopixel, pygame, pyaudio, OpenAI
- You may need to set up an ALSA file to tell the Raspberry to treat the default microphone as the one we just plugged in, I got lucky and did not have to for the second microphone I test
- From here the RPOS setup is done
Wiring the Pi Zero 2W
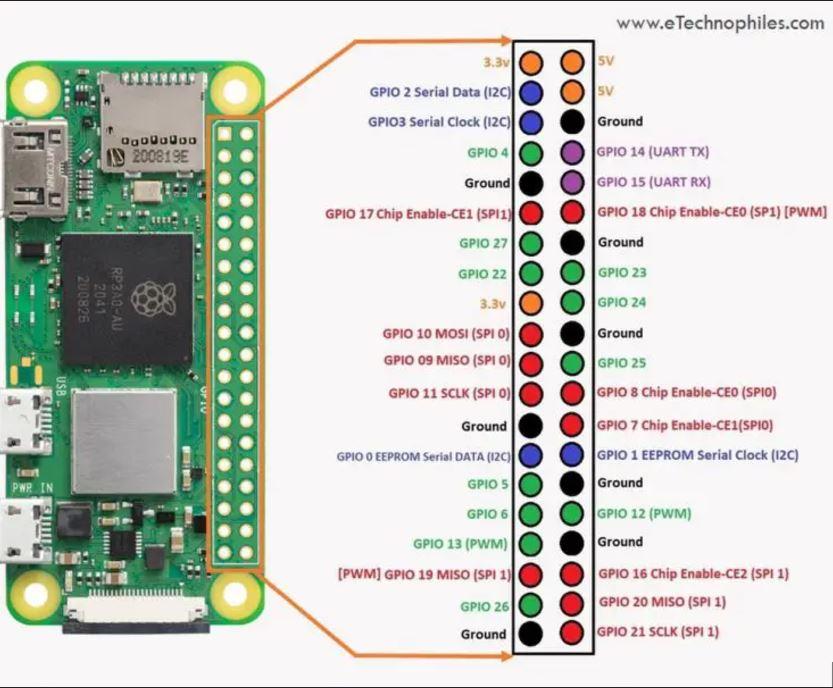
Our wiring is very simple:
- Wire any button with one wire to any ground, one to any signal, I used GP17 for mine
- Wire Neopixel's Power to a 5V out, I chose pin 2
- Wire Neopixel's ground to any ground, and signal to any signal EXCEPT GP10, this is a known issue, GP10 will cause the strip to flicker uncontrollably without a level shifter
- Funny enough GP10 is the the only pin NeoPixel module can use without running the script in Sudo.
- Just connect the NeoPixel signal to any GPIO and I will handle the access issue below
- Alternatively we can use an Adafruit TFT Gizmo which looks great if you do not print the body too big (link to the wire map for that)
- Now plug USB microphone into a USB slot on the micro USB to USB splitter and connect your blue tooth speaker.
Now We May Begin to Code
2) We can now set up our code
- I simply set this as a python file on my desktop
- Also I attempted to make all path's variable so this should be used by anyone, all it requires is a GPT API key and about 10 cents in credits for hours of usage
- This is not to bad and I will include my relevant functions here that worked for me:
<PYTHON>
client = OpenAI(
api_key=api_keyer, # This is the default and can be omitted
)
#Define a way to record sound
def Sound_Record():
time.sleep(5)
#Define a sender function to GPT
def Send_To_GPT(User_Message, Mission):
chat_completion = client.chat.completions.create(
messages=[
{
"role":"system",
"content":Mission
},
{
"role": "user",
"content": User_Message,
}
],
model="gpt-3.5-turbo",
)
return chat_completion.choices[0].message.content
# Send out some text and get back some speech
def save_audio_stream(model: str, voice: str, input_text: str, file_path: str):
""" Saves streamed audio data to a file, handling different OS path conventions. """
# Construct the path object and validate the file extension
path = Path(file_path)
valid_formats = ['mp3', 'opus', 'aac', 'flac', 'wav', 'pcm']
file_extension = path.suffix.lstrip('.').lower()
if file_extension not in valid_formats:
raise ValueError(f"Unsupported file format: {file_extension}. Please use one of {valid_formats}.")
client = OpenAI(api_key=api_keyer)
try:
with client.audio.speech.with_streaming_response.create(
model=model,
voice=voice,
input=input_text,
response_format=file_extension
) as response:
with open(path, 'wb') as f:
for chunk in response.iter_bytes():
f.write(chunk)
except OpenAIError as e:
print(f"An error occurred while trying to fetch the audio stream: {e}")
# Define a system to record an audio snippet
def recording_sounds():
# Set parameters for the recording
FORMAT = pyaudio.paInt16 # Audio format (16-bit)
CHANNELS = 1 # Mono sound
RATE = 44100 # Sample rate (44.1kHz)
CHUNK = 1024 # Size of each audio chunk
RECORD_SECONDS = 5 # Duration of recording
OUTPUT_FILENAME_WAV = "output.wav" # Temporary WAV file name
# Initialize the PyAudio object
p = pyaudio.PyAudio()
# Open the stream to record audio
stream = p.open(format=FORMAT,
channels=CHANNELS,
rate=RATE,
input=True,
frames_per_buffer=CHUNK)
pixels.fill((255,0,0))
print("Recording...")
frames = []
# Record audio
for _ in range(0, int(RATE / CHUNK * RECORD_SECONDS)):
data = stream.read(CHUNK)
frames.append(data)
# Stop the stream and close it
print("Recording finished.")
stream.stop_stream()
stream.close()
p.terminate()
pixels.fill((0,255,255))
print("Current working directory:", os.getcwd())
time.sleep(5)
# Save the recorded audio to a WAV file
with wave.open(OUTPUT_FILENAME_WAV, 'wb') as wf:
wf.setnchannels(CHANNELS)
wf.setsampwidth(p.get_sample_size(FORMAT))
wf.setframerate(RATE)
wf.writeframes(b''.join(frames))
print(f"WAV file saved as {OUTPUT_FILENAME_WAV}")
#Now let us define a speech to texter:
def stt(path, file):
audio_file= open(path+file, "rb")
transcription = client.audio.transcriptions.create(
model="whisper-1",
file=audio_file
)
return transcription
#Play Audio Function
# Path to the audio file
def Audio_Play(pather_with_file):
# Check if the file exists
# Initialize the mixer for playing sounds
pygame.mixer.init()
# Load and play the audio file
pygame.mixer.music.load(pather_with_file)
pygame.mixer.music.play()
# Wait for the music to finish playing
while pygame.mixer.music.get_busy():
pygame.time.Clock().tick(10)
- For the GPT context I have files being read in from .txt documents pertaining to my classes but any string describing the usage can be passed into this function
- My general structure is, on button press, we call these functions in order.
- This I think leads to some very neat outputs
Calling This Code
- This is a real pain because of neo pixel handling pin inputs
- We must then call this in Sudo, however this messes with our audio environment
- Here is what we must do to fix this, note that you need replace "your_user" with your set username (possibly is "root"or "pi")
<BASH>
...: cd Desktop
...: pulseaudio -k
...: pulseaudio --start
...: export SDL_AUDIODRIVER=alsa
...: export PULSE_SERVER=unix:/run/user/$(id -u your_user)/pulse/native
...: sudo -E python3 project.py
- This was kind of a miracle this worked out for me. First this restarts the pulseaudio process
- We then set out exported driver to ALSA which worked the best for me (also possibly is the driver for the microphone handling above)
- Then we export the PULSE_SERVER from our local session
- Nonpixel will not work with the pins unless we run this sudo, and audio will not work with sudo unless we export the audio environment so this is my less than elegant solution.
Enjoy
Enjoy your work (as such)